- Published on
BA024. EXAWin 베이지안 엔진의 진화: 데이터가 스스로 파라미터를 튜닝하는 날
EXA 베이지안 엔진(BA020)이 영업 수주 확률의 안개를 걷어낸 지 6개월(BA02.[Exa 베이지안추론] 영업의 보이지 않는 손: 60일의 도박). 영업 본부장은 시스템의 판단을 신뢰하게 되었고, 팀은 데이터 기반의 의사결정에 익숙해졌다. 하지만 딜이 쌓이고, 시간이 흐르면서 그는 한 가지 불편한 사실과 마주하게 된다 — 엔진의 '초기 설정값'은 여전히 그가 직감으로 입력한 것이었다.
이 이야기는 영업 엔진이 '인간의 직감'에서 벗어나 '데이터의 자기학습'으로 진화하는 순간을 다룹니다. 그 진화의 이름은 Auto-Tuner입니다.
1장. 균열
봄비가 유리창을 두드리는 3월의 어느 금요일 오후였다.
영업 본부장 — 이제 사내에서 '데이터 영업의 선구자'로 불리는 — 은 분기 리뷰를 마치고 자리로 돌아왔다. 표정이 좋지 않았다. CEO 앞에서 자신 있게 발표한 지 30분밖에 지나지 않았는데, 뭔가가 그의 속을 계속 긁고 있었다.
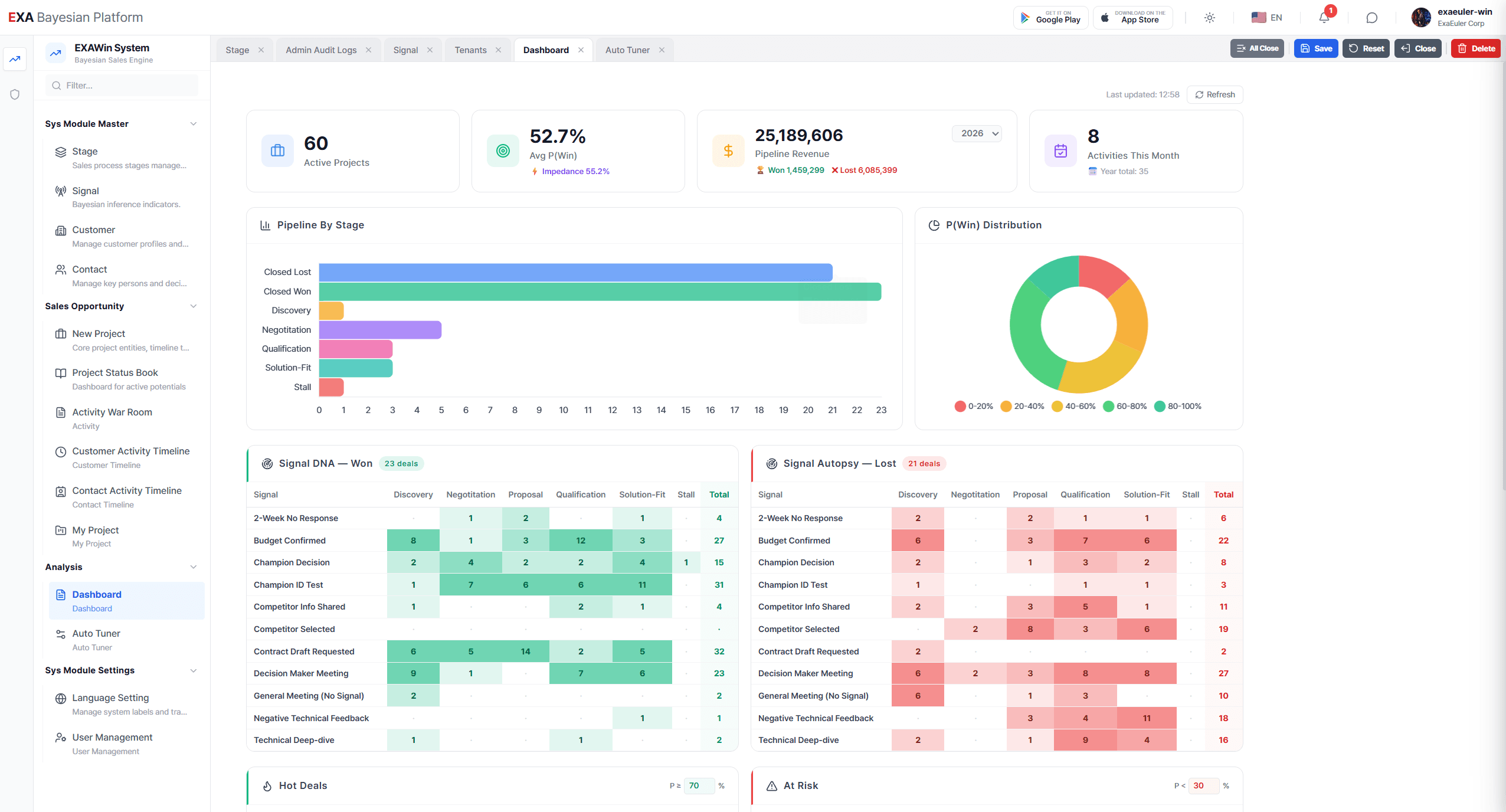
에너지A 프로젝트의 성공 이후, 열두 개의 딜이 추가로 시스템을 거쳤다. 결과는? 여덟 건 수주, 네 건 실패. 성공률 67%. 나쁘지 않다. 하지만 문제는 성공이 아니라 실패에 있었다.
네 건의 실패 중 세 건에서, 시스템은 최종 단계까지 60% 이상의 수주 확률을 보여주고 있었다. 그리고 졌다.
"박 차장, 이거 봐."
그는 태블릿을 옆자리에 내려놓았다.
"프로젝트 델타, 확률 68%에서 실패. 프로젝트 감마, 72%에서 실패. 엔진이 '된다'고 했는데 안 된 거야."
박 차장이 눈살을 찌푸렸다. "엔진이 틀린 겁니까?"
"틀린 게 아니야." 본부장이 커피를 한 모금 삼켰다. "엔진은 제대로 돌아갔어. 문제는… 엔진에게 넣어준 초기 설정값이야."
그는 6개월 전을 떠올렸다. 시스템을 처음 도입할 때, 각 영업 단계(Stage)에 부여할 가중치(T값)와 시그널의 민감도(k값)를 직접 설정했다. 어떤 근거로? 20년의 경험과 '감(感)'이었다.
Discovery 단계의 T값: 0.3. Qualification 단계: 0.6. Solution-Fit: 0.8.
그 숫자들은 그의 직관이 빚어낸 조각품이었다. 그리고 당시에는 그것이 최선이었다.
하지만 이제 100건이 넘는 과거 딜 데이터가 시스템에 축적되어 있었다. 50건의 수주와 50건의 실패 — 성공과 실패의 패턴이 뚜렷하게 기록된 가장 정직한 교과서. 그런데 엔진은 여전히 6개월 전 '감'으로 설정한 파라미터로 돌아가고 있었다.
그것은 마치 1년 넘게 운전한 차의 사이드미러를 딜러가 출고할 때 맞춰놓은 각도로 쓰고 있는 것과 같았다. 운전은 할 수 있다. 하지만 사각지대가 있다.
"우리가 설정한 T값과 k값이 실제 데이터랑 안 맞는 거 아닐까?"
박 차장이 고개를 끄덕였다. "그런데… 맞는 값을 어떻게 찾습니까? 조합이 수천 개인데."
본부장은 화면을 터치했다. 대시보드 왼쪽에 6개월 전엔 없었던 버튼이 하나 있었다. 보라빛으로 은은하게 빛나는, 처음 보는 아이콘.
[Auto-Tuner]
2장. 수천 개의 갈림길 — Grid Search
그가 버튼을 누르자, 화면이 어두워지며 새로운 인터페이스가 열렸다. 화면 중앙에 간결한 문장이 떠올랐다.
Auto-Tuner는 귀사의 과거 영업 데이터를 학습하여 최적의 베이지안 파라미터를 계산합니다. 지금까지 축적된 106건의 딜 데이터가 감지되었습니다. 최적화를 시작하시겠습니까?
그는 주저 없이 [시작] 버튼을 눌렀다.
첫 번째 단계가 가동되었다. 화면에 격자(Grid)가 펼쳐졌다. 마치 서울 도심의 항공 사진처럼, 수천 개의 점이 빼곡히 들어찬 2차원 평면이 눈앞에 나타났다.
Phase 1: Grid Search — 최적 파라미터 탐색 중
스캔 중: 3,240개의 T/k 파라미터 조합
"이게 뭔가요?" 박 차장이 물었다.
본부장은 설명을 읽었다. Grid Search. 시스템이 T값(각 영업 단계의 가중치)과 k값(시그널 민감도)의 가능한 모든 조합을 체계적으로 탐색하는 과정이었다. 마치 금속 탐지기를 들고 해변의 모래밭을 센티미터 단위로 스캔하듯, 최적의 '달콤한 지점(Sweet Spot)'을 찾아가고 있었다.
격자 위의 점들이 하나씩 색깔을 바꾸기 시작했다. 파란색은 낮은 정확도. 초록색은 보통. 빨간색으로 갈수록 높은 정확도. 화면 한쪽에는 Youden's J 지수라는 숫자가 실시간으로 뛰고 있었다.
"J 지수가 뭡니까?"
본부장이 화면의 도움말을 가리켰다.
"'진짜 될 딜'을 맞추는 능력(민감도)과, '안 될 딜'을 걸러내는 능력(특이도)의 합이래. 이 두 가지를 동시에 최대화하는 파라미터 조합을 찾는 거야."
화면의 격자 위에서, 하나의 영역이 유독 진한 빨간색으로 물들기 시작했다. 3,240개의 조합 중, 수학은 그 자리를 가리키고 있었다.
30초. 그것이 Grid Search가 '최적 후보'를 찾는 데 걸린 시간이었다.
Grid Search 완료
최적 후보: T(Discovery)=0.22, T(Qualification)=0.51, T(Solution-Fit)=0.87, k=1.34
Youden's J = 0.74
진행: Phase 2로 이동합니다.
본부장은 숫자를 비교했다. 자신이 6개월 전 '감'으로 설정한 T(Discovery)=0.30과, 데이터가 찾아낸 0.22. 그 차이가 의미하는 바는 명확했다.
"내가 Discovery 단계를 과대평가하고 있었어. 초기 미팅에서 좋은 반응을 받으면 '되겠다'고 흥분했거든. 근데 데이터는 말하고 있잖아 — Discovery 단계의 반응은 생각보다 수주에 크게 기여하지 않는다고."
반대로 Solution-Fit 단계의 가중치는 0.80에서 0.87로 올라갔다. 기술 적합성 검증 단계에서의 시그널이 수주에 결정적이라는, 100건의 데이터가 증명한 사실이었다.
3장. 입자 폭풍 — MCMC 앙상블 샘플링
하지만 Grid Search는 시작일 뿐이었다. 화면이 전환되며, 두 번째 단계가 열렸다.
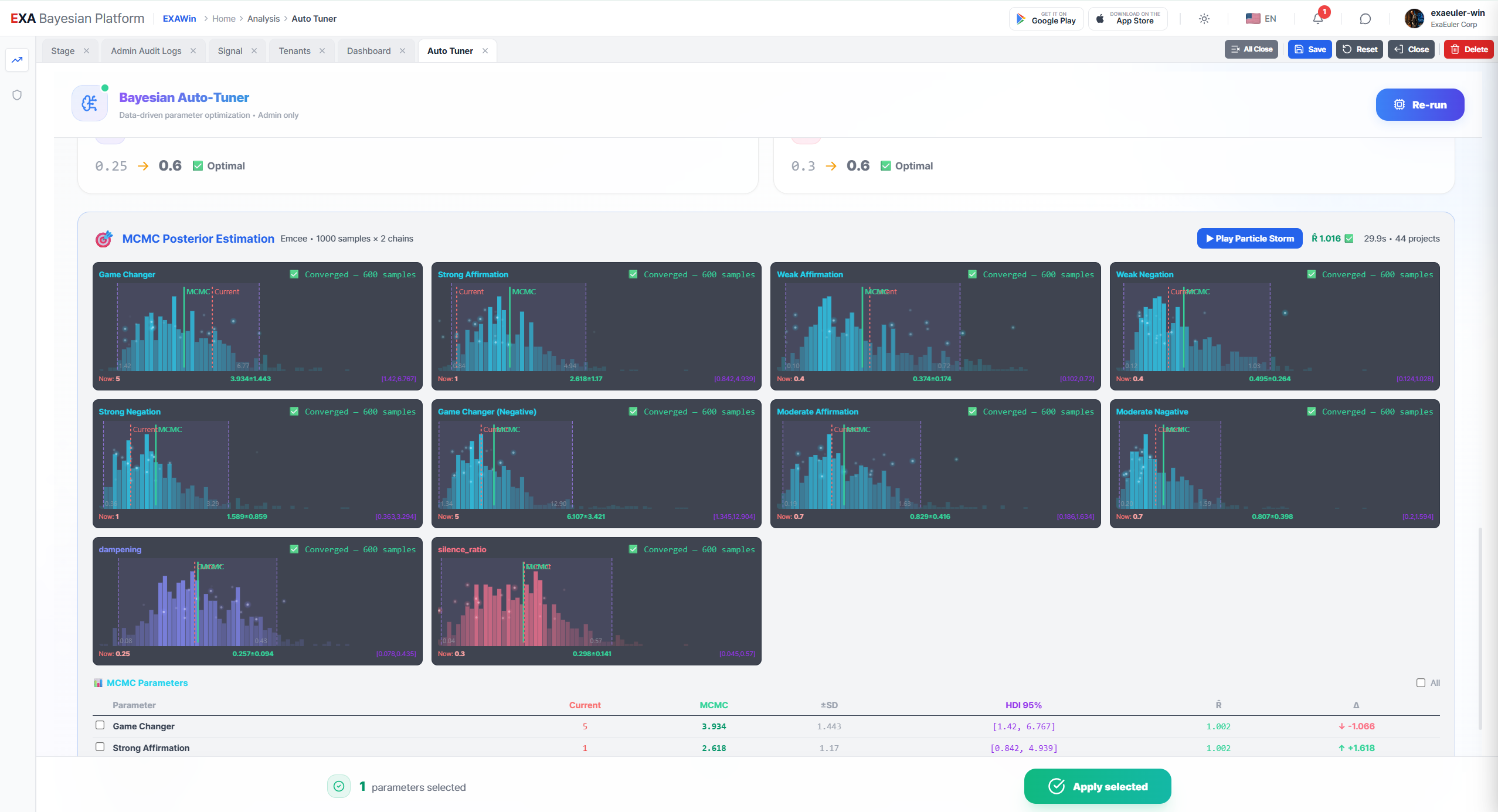
Phase 2: MCMC Ensemble Sampling — 사후분포 추론
Emcee 앙상블 샘플러 가동. 워커 수: 256
화면이 어둡게 변하더니, 수백 개의 빛나는 입자(Particle)가 화면 위에 흩뿌려졌다. 마치 밤하늘에 반딧불이 수백 마리가 일제히 날아오르는 것 같았다.
"이건 또 뭡니까?" 어느새 옆에 와 있던 김 과장이 입을 벌린 채 물었다.
"MCMC. Markov Chain Monte Carlo." 본부장이 읽었다. "수백 개의 '워커(Walker)'가 동시에 파라미터 공간을 탐색해. Grid Search가 '가장 좋은 한 점'을 찾았다면, 이건 '그 점 주변이 얼마나 확실한지'를 검증하는 거야."
입자들이 움직이기 시작했다. 처음에는 무질서해 보였다. 어떤 입자는 위로, 어떤 입자는 아래로, 서로 다른 방향으로 흩어졌다. 하지만 시간이 지나면서 패턴이 나타났다. 입자들이 하나의 영역으로 서서히 수렴하기 시작한 것이다.
"보여요? 저 입자들이 모이는 곳이 있어요."
박 차장이 가리킨 곳에서 입자들의 밀도가 높아지고 있었다. 마치 별이 태어나는 성운(Nebula)처럼, 수백 개의 궤적이 하나의 중심으로 빨려 들어갔다.
화면 아래에 숫자가 나타났다.
수렴 진단 (R-hat)
T(Discovery): R̂ = 1.002
T(Qualification): R̂ = 1.004
T(Solution-Fit): R̂ = 1.001
k: R̂ = 1.003
"R-hat이 전부 1.00대면 뭐가 좋은 겁니까?"
본부장이 웃었다. "수학이 '이 결과를 믿어도 된다'고 보증하는 거야. 256명의 탐험가가 각자 다른 길로 들어갔는데, 결국 같은 보물 위치에 도달했어. 한두 명이 찾은 게 아니라 256명 전원이 합의한 거야."
그리고 그것이 이 과정의 핵심이었다. Grid Search가 "이 언덕이 가장 높습니다"라고 알려줬다면, MCMC는 "그리고 이 언덕의 높이가 정확히 87.3미터라는 것을 95% 신뢰도로 보증합니다"라고 확인해 주는 것이었다.
화면에 최종 결과가 떴다.
HDI 95% 신뢰구간
T(Discovery): 0.19 ~ 0.25 (최적: 0.22)
T(Solution-Fit): 0.83 ~ 0.91 (최적: 0.87)
k: 1.28 ~ 1.41 (최적: 1.34)
"신뢰구간이라…" 본부장이 중얼거렸다.
그것은 단순한 '정답'이 아니라, '정답의 범위'였다. T(Discovery)의 최적값은 0.22이지만, 0.19에서 0.25 사이 어디에 놓아도 95%의 확률로 안전하다는 뜻이었다. 엔진이 한 가지 답만 고집하지 않고, '믿을 수 있는 범위'까지 알려주는 것. 그것이 MCMC가 Grid Search 위에 얹어주는, 결정적인 확신의 무게였다.
4장. 거울 — 교차검증
세 번째 단계가 시작되었을 때, 화면의 톤이 바뀌었다. 따뜻한 보라빛에서 차가운 청록색으로. 마치 수술실의 조명 같았다.
Phase 3: 5-Fold Cross-Validation — 과적합 검증
"과적합이요?" 김 과장이 고개를 갸웃했다.
본부장이 설명했다. "시험문제 답안지를 외워서 100점 맞은 학생이랑, 진짜 이해해서 80점 맞은 학생이 있어. 과적합은 전자야. 과거 데이터에 너무 딱 맞춰진 파라미터는, 새로운 딜에서 오히려 틀릴 수 있거든."
시스템이 106건의 데이터를 다섯 묶음(Fold)으로 나눴다. 그리고 네 묶음으로 학습한 뒤, 나머지 한 묶음으로 시험을 치렀다. 이 과정을 다섯 번 반복했다. 마치 의대의 임상시험처럼, 같은 약이 다른 환자 그룹에서도 효과가 있는지 검증하는 것이었다.
교차검증 결과
Fold 1: 정확도 76.2%
Fold 2: 정확도 74.8%
Fold 3: 정확도 73.9%
Fold 4: 정확도 77.1%
Fold 5: 정확도 75.4%
평균 정확도: 75.5% (±1.2%)
✅ 과적합 없음 — 일반화 성능 양호
분산이 1.2%에 불과했다. 어떤 데이터 묶음을 빼놓고 학습해도, 거의 같은 성능을 내고 있었다. 엔진이 과거에 '과잉 적응'하지 않았다는 증거였다.
하지만 진짜 반전은 그다음이었다.
Signal Lift 분석 — 시그널별 기여도
화면에 막대 그래프가 나타났다. 시스템에 등록된 12개의 시그널이 순서대로 나열되어 있었고, 각 시그널이 수주 확률에 얼마나 기여하는지가 색깔과 높이로 표시되어 있었다.
"이걸 보세요."
박 차장이 화면을 손가락으로 짚었다. '경쟁사 정보 공유'라는 시그널의 막대가 유독 높았다. Lift 값 +3.2. 고객이 경쟁사의 가격이나 제안 내용을 우리에게 흘렸을 때, 수주 확률이 3.2배 상승한다는 뜻이었다.
반면, '회의 참석 인원 증가'라는 시그널의 막대는 거의 바닥에 붙어 있었다. Lift 값 +0.3.
"회의에 사람 많이 나오면 관심 있다고 생각했는데…" 김 과장이 멋쩍게 웃었다.
"그게 소위 '착시'야." 본부장이 말했다. "회의에 10명이 나온다고 수주가 잘 되는 게 아니야. 데이터가 말하고 있잖아 — 시끌벅적한 건 구경이고, 진짜 시그널은 고객이 경쟁사 카드를 은밀하게 보여줄 때야."
그리고 마지막으로, 시스템은 하나의 경고를 띄웠다.
⚠️ Mismatch Alert
시그널 '예산 승인'의 현재 Impact Score(2.5)는 데이터 기반 권장값(1.7)과 불일치합니다.
과대 설정된 파라미터는 False Positive(헛된 기대)를 유발할 수 있습니다.
"예산 승인이 확정되면 거의 된 거 아닙니까?"
본부장이 고개를 저었다. "예전에는 그랬어. 근데 요즘은 예산 승인 나고도 뒤집히는 경우가 많아졌거든. 조직 개편이나 전략 변경으로. 데이터가 그걸 잡아낸 거야."
5장. 보정
세 개의 단계 — Grid Search, MCMC, Cross-Validation — 가 모두 완료되었다. 화면 중앙에 최종 결과가 떠올랐다.
Auto-Tuner 최적화 완료
데이터 기반 파라미터 vs 기존 파라미터
| 파라미터 | 기존 (수동) | 최적값 (Auto-Tuner) | 변화 |
|---|---|---|---|
| T(Discovery) | 0.30 | 0.22 | ▼ 과대평가 보정 |
| T(Qualification) | 0.60 | 0.51 | ▼ 미세 조정 |
| T(Solution-Fit) | 0.80 | 0.87 | ▲ 핵심 단계 강화 |
| T(Negotiation) | 0.90 | 0.92 | ▲ 미세 조정 |
| k(시그널 민감도) | 1.50 | 1.34 | ▼ 과민 반응 억제 |
Youden's J 지수: 0.52 → 0.74 (42% 향상)
이 파라미터를 적용하시겠습니까?
본부장은 숫자들을 천천히 훑었다. 테이블 위의 비교가, 6개월간 그가 품고 있었던 미세한 오차의 정체를 적나라하게 보여주고 있었다.
Discovery를 과대평가해서, 초기 미팅이 잘 되면 '이미 된 딜'처럼 느끼게 했다. 시그널 민감도(k)를 과하게 설정해서, 작은 긍정 신호에도 확률이 과도하게 뛰었다. 결국 중후반에서 '된다'고 믿었던 딜들이 무너진 것이다.
"적용해."
그는 버튼을 눌렀다. 화면의 그래프가 실시간으로 다시 그려졌다. 과거 106건의 딜에 새 파라미터가 소급 적용되자, 실패한 세 건의 딜(델타, 감마, 시그마) — 68%, 72%, 61%를 보이던 — 이 45%, 38%, 42%로 재계산되었다.
"보여?" 그가 박 차장에게 말했다. "새 파라미터로는 이 딜들이 50%도 안 됐어. 시스템이 '위험하다'고 정확히 가리켰을 거야. 우리가 낙관 편향에 빠지지 않았을 거라고."
에필로그. 스스로 진화하는 엔진
그날 밤, 사무실에 혼자 남은 본부장은 창밖의 도시 불빛을 바라보며 생각했다.
6개월 전, 그는 자기 직감만으로 80%를 외쳤다가 엔진의 26.4%에 뺨을 맞았다. 그리고 엔진을 믿었고, 수주에 성공했다. 하지만 그 엔진조차 '인간의 직감'이 설정한 초기값 위에서 돌아가고 있었다는 사실을, 오늘에서야 깨달았다.
Auto-Tuner가 한 일은 단순했다. 인간이 설정한 파라미터를, 인간이 만든 데이터로 검증하고, 수학이 최적값을 찾아낸 것이다. 그 과정에서 인간에게는 보이지 않았던 편향(Bias)이 드러났고, 데이터가 그것을 교정했다.
Grid Search가 3,240개의 가능성 중 최적의 후보를 찾았고, MCMC의 256개 워커가 그 후보를 엄밀하게 검증했으며, 5-Fold 교차검증이 '미래에도 통할 것인가'를 시험했다.
세 개의 도구는 하나의 질문에 답하고 있었다.
"당신의 엔진이 지금 보고 있는 세상은, 실제 세상과 얼마나 같습니까?"
본부장은 태블릿을 덮으며 혼자 중얼거렸다.
"6개월 전에는 내가 엔진을 조율했다. 오늘부터는 데이터가 엔진을 조율한다. 그리고 나는… 엔진이 가리키는 방향으로 핸들을 꺾기만 하면 된다."
화면이 꺼진 어둠 속에서도, 수백 개의 보이지 않는 입자들은 여전히 움직이고 있었다. 다음 딜의 데이터를 기다리며, 더 정밀한 확률의 지도를 그릴 준비를 하면서.
[기술 부록] Auto-Tuner의 세 기둥
Auto-Tuner는 세 가지 수학적 엔진의 협업으로 작동합니다.
1. Grid Search 최적화
- 각 영업 단계(Stage)의 가중치(T)와 시그널 민감도(k)의 모든 가능한 조합을 체계적으로 탐색합니다.
- Youden's J 지수(민감도 + 특이도 - 1)를 극대화하는 최적 조합을 식별합니다.
- 매개변수 공간의 전수 조사를 통해, 지역 최적해(Local Optimum)에 갇히지 않습니다.
2. MCMC 앙상블 샘플링 (Emcee)
- Goodman-Weare의 아핀 불변 앙상블 샘플러를 사용합니다.
- 256개의 병렬 워커가 사후분포(Posterior Distribution)의 전체 지형을 탐색합니다.
- R-hat 수렴 진단을 통해 결과의 신뢰성을 보증하고, HDI(Highest Density Interval) 95% 신뢰구간을 제공합니다.
3. 5-Fold 교차검증 및 진단
- 데이터를 5등분하여, 학습과 검증을 교차 수행합니다.
- Signal Lift 분석으로 각 시그널의 실질 기여도를 측정합니다.
- Mismatch 경고로 사용자 설정값과 데이터 기반 최적값의 괴리를 알립니다.
📡 다음 편 예고
BA025. 최적의 경계를 찾아서 — Grid Search와 Youden's J의 수학
3,240개의 격자 위에서, 엔진은 어떻게 '진짜 될 딜'과 '안 될 딜'을 가르는 최적의 경계선을 찾았을까? 민감도와 특이도의 줄다리기, ROC 곡선 위의 달콤한 지점, 그리고 Youden's J 지수가 영업 파라미터를 조율하는 수학적 원리를 풀어냅니다.
BA026. 입자들의 합의 — MCMC 앙상블과 교차검증의 수학
256개의 워커가 사후분포의 지형을 탐색하는 Emcee 알고리즘, R̂ 수렴 진단의 의미, 그리고 5-Fold 교차검증이 과적합의 망령을 퇴치하는 과정. 소설이 '왜'를 물었다면, 이 두 편은 '어떻게'에 답합니다.
Bayesian EXAWin-Rate Forecaster
매 미팅과 협상에서 포착되는 미세한 신호를 베이지안 업데이트로 실시간 분석하여 영업 성공 확률을 정교하게 예측합니다. EXAWin과 함께라면 직관의 영역이었던 영업이 가장 완벽한 데이터 과학으로 진화합니다.


