Bayesian Application: Prior Alpha, Beta
The principles behind setting the Bayesian engine Prior α/β and the automatic learning roadmap
This article was written to provide EXAWin users with an in-depth explanation of the system's core — the Bayesian engine, particularly the principles behind configuring Prior / and the automatic learning roadmap. It's too deep for a help screen, yet too important to omit.
You don't need to disassemble and reassemble an engine just to drive a car. But a driver who understands how the engine works drives better. They understand why the accelerator responds the way it does, they don't panic when a warning light comes on, and they intuitively grasp the car's limits and possibilities. The same applies to EXAWin's Bayesian engine. Understanding its workings means you won't blindly follow the numbers the system produces — instead, you'll comprehend why those numbers are what they are, trust the system, and maximize its utility.
This article is a journey toward that understanding.
EXAWin's Bayesian engine uses the NSBI (Normalized Sequential Bayesian Inference) model. We now begin the story of how this engine transforms a company's intangible assets — intuition, experience, market sense — into 💡 Prior (prior probability), a solid mathematical language, and how qualitative experience is translated into precise mathematical language to meet 70 years of statistical achievement, evolving into a self-improving intelligent engine.
Before or after reading this article, if you want a deeper understanding of the overall picture of EXAWin's Bayesian engine, please consult the following series. The EXAWin Bayesian engine operates on the structural premises described in Appendices 1, 2, and 3 below:
- EXA Bayesian Inference: The Invisible Hand of Sales, 60-Day Gamble — Using a novel format, this vividly depicts how EXAWin operates in the actual sales field. Following a sales team through a 60-day project as they make decisions based on the system's probability predictions, you'll naturally feel why the mathematics in the appendices below is necessary.
Appendices 1-3 below are technical commentaries dissecting the internals of the EXAWin engine featured in the above story:
- Appendix 1. The Bayesian Engine: Mathematical Alchemy for Managing Uncertainty — Dissects the conjugate relationship between Beta and Binomial distributions and the architecture of Recursive Bayesian Estimation. See how the same lineage as NASA's Kalman Filter applies to the sales field.
- Appendix 2. The Paradox of Silence: Information Entropy and Log-Weighted Geometry — Mathematizes the most dangerous ghost in business, 'Silence,' using entropy and the Weber-Fechner law. Reveals the information-theoretic basis for why probability changes even on days with no data.
- Appendix 3. Sales Success Probability Decision System: Decision Impedance, Thresholds, and the Acceleration of Conviction — Through log-odds accumulation and sigmoid correction, designs a decision filter that bridges the gap between 'mathematical probability' and 'psychological conviction.' Shows the structural reason why the number 51% is insufficient for making a decision.
Prologue: Every Prediction Begins with a Bias
"A prediction without bias does not exist."
This statement may sound provocative, but it is one of the most fundamental consensuses of modern statistics. A single posthumous paper left by 18th-century English Presbyterian minister Thomas Bayes (1701-1761) forever changed how humanity confronts uncertainty. His core insight was remarkably simple: By combining what we already know (prior belief) with what we newly observe (data), we can arrive at better knowledge (posterior belief).
This principle has become the universal framework powering decision engines of modern civilization — from spam filters, autonomous driving, drug development, weather forecasting, to financial risk modeling. And now, to answer the hardest question in the sales field — "Can this project succeed?" — the same principle pulses at the heart of EXAWin.
This article unfolds in a single narrative — from the theoretical roots to practical application — how EXAWin's Bayesian engine transforms a company's empirical intuition into the language of mathematics, and how it operates as an intelligent system that evolves itself as data accumulates. There's no need to fear the formulas. Before every formula, your intuition will always guide you first.
Chapter 1. Bayes' Theorem: The Most Powerful Learning Formula — 200 Years Old
Every story begins with a single formula. Bayes' Theorem provides the only mathematically consistent answer to the question: "When new evidence appears, how should we update our existing beliefs?"
Each element translates into the language of the sales field:
| Mathematical Symbol | Sales Field Language | Meaning |
|---|---|---|
| Prior | Probability of success estimated from past experience alone, without data | |
| Likelihood | How well the currently observed sales activity is explained under this success rate | |
| Posterior | Updated probability of success after incorporating evidence | |
| Evidence | Overall probability of the data considering all hypotheses (normalizing constant) |
The philosophical revolution of this formula lies in recognizing , the Prior, as a legitimate starting point. Traditional frequentist statistics insisted "only data can speak" and rejected the involvement of prior knowledge. But real-world decision makers — doctors, judges, investors, and sales leaders — must constantly make judgments even when there isn't a single data point. Bayes' Theorem mathematically embraces this reality.
1.1 Sequential Learning: Yesterday's Conclusion Is Today's Starting Point
The most elegant property of Bayes' Theorem is that sequential updating is possible. Today's Posterior becomes tomorrow's Prior. This recursive structure is the foundation of EXAWin's real-time learning engine.
After observing the first datum :
After observing the second datum :
After observing through the -th datum:
The implication is clear. EXAWin automatically recalculates the success probability every time a sales activity (meeting, proposal, demo) is recorded. Like an analyst who never sleeps, the system grows by consuming evidence, never discarding a single piece of information from the first meeting to the last negotiation signal.
Chapter 2. The Beta Distribution: A Tool for Reasoning About the Probability of Probability
2.1 "Can We Say the Success Rate Is Exactly 32.7%?"
In reality, fixing a project's success rate to a single number is dangerous self-deception. A statement closer to the truth is: "The success rate is probably somewhere between 25% and 40%, with 30% being most likely." The mathematical tool specialized for expressing this uncertainty about the probability itself is the 💡 Beta Distribution.
The Beta distribution was designed to model random variables taking values between 0 and 1, and its shape is completely determined by two shape parameters and . Its probability density function (PDF) is:
Where is the Beta function, which normalizes so the total probability equals 1:
is the Gamma function, where for natural number , .
Don't be intimidated by the formula's appearance. The key is that just two numbers and can completely describe the "distribution of belief about success."
2.2 Intuitive Interpretation of α and β: Virtual Experiment Records
The most intuitive way to understand and is as "results of virtual experiments that haven't happened yet."
| Parameter | Business Interpretation | Mathematical Role |
|---|---|---|
| Number of virtual times considered "successful" | Pushes the distribution rightward (toward higher probability) | |
| Number of virtual times considered "failed" | Pushes the distribution leftward (toward lower probability) | |
| Total virtual experiment count = Strength of conviction | Makes the distribution sharper (narrower) |
From this interpretation, the key statistics of the Beta distribution emerge naturally.
Expected Value (Mean) — The success rate we believe is "most plausible":
Variance — How much that belief fluctuates:
Mode — The peak of the distribution, the most likely value (when ):
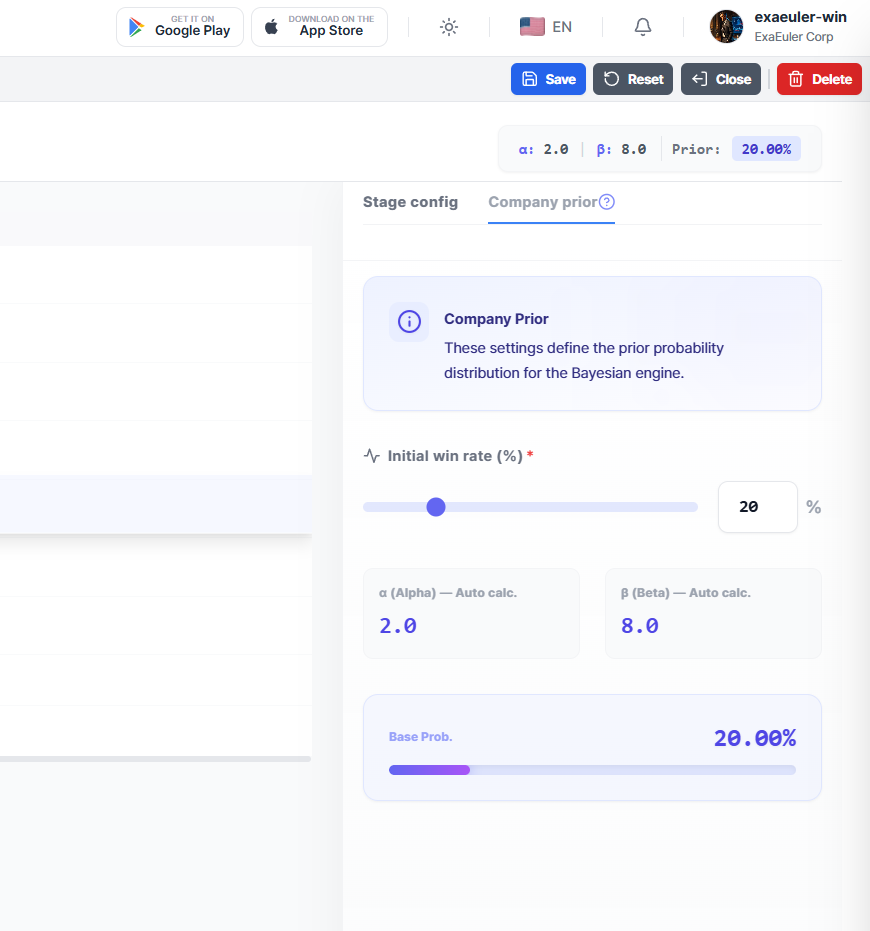
2.3 Concrete Example: The Moment a Company's Intuition Becomes a Formula
Suppose a company's sales director says:
"Our company typically wins about 1 in 5 projects, and this pattern is fairly consistent."
From this single piece of intuition, EXAWin extracts two numbers:
- Expected success rate: (20%)
- Strength of conviction: Moderate (not rock-solid, but experience-based)
Setting this as , :
This variance of 0.0145 translates to a standard deviation of approximately 0.12, meaning the uncertainty of the success rate is roughly percentage points. "We believe 20%, but it could be anywhere from 8% to 32%" — honest self-awareness projected into a formula.
If the same 20% expected value comes with stronger conviction — say, from a company with hundreds of historical data points — it could be set to , :
The variance decreased from 0.0145 to 0.0016, approximately 9 times smaller. Same "20%" belief, but the latter is far more solid conviction. This is the role of , the "Precision" of information. The larger it is, the sharper the distribution, and the smaller the influence of each new data point. Conversely, the smaller it is, the wider the distribution, and the more sensitively the system responds to new evidence.
Chapter 3. Conjugate Prior Distribution: Where Mathematical Elegance Meets Practicality
3.1 The Beta-Binomial Conjugate Relationship
The Beta distribution was chosen as Prior not out of aesthetic preference but out of mathematical necessity. The outcome of a sales project (success/failure) follows a Binomial Distribution. And the Beta distribution is the 💡 conjugate prior of the Binomial distribution. This means the prior and posterior distributions belong to the same distribution family, and updates happen in closed form.
Given trials (sales activities) with successes observed, the Binomial likelihood is:
When the Prior is , the posterior distribution is:
This is again the form of a Beta distribution:
Savor the elegance of this result. The observed number of successes is added to , and the number of failures is added to . As if actual experience points naturally accumulate on top of virtual past records.
3.2 Dynamics of Updating: The Structure of the Posterior Mean
Expanding the expected value of the updated success rate reveals an interesting structure:
This can be restructured as a weighted average:
This formula summarizes EXAWin's engine behavior in a single line:
- When data is scarce (small ): Prior weight is large → The company's empirical intuition dominates predictions
- As data accumulates (larger ): Data weight grows → Actually observed success rates dominate predictions
- In the limit (): Posterior mean → Observed success rate → Prior's influence completely vanishes
This is the Bayesian system's self-correction ability. No matter what Prior is initially set, with enough data, truth reveals itself. In statistics, this property is called 💡 posterior consistency, and it is a mathematically proven theorem.
Chapter 4. The 70-Year Pursuit: Empirical Bayes — When Data Surpasses the Teacher
4.1 Herbert Robbins's Revolutionary Question (1956)
In 1956, mathematical statistician Herbert Robbins of Columbia University presented a paper at the Third Berkeley Symposium on Mathematical Statistics that ignited a quiet revolution: "An Empirical Bayes Approach to Statistics."
His question was bold: "Can we estimate the Prior from the data itself, without subjective specification?"
This was an oblique yet profound answer to the decades-long philosophical debate between Bayesians and frequentists. Robbins showed that when multiple related problems exist simultaneously — for example, when a company manages dozens of sales projects at once — individual problem data can be pooled to reverse-estimate structural patterns of the entire population.
This idea is called 💡 Empirical Bayes.
4.2 Efron and Morris's Baseball Story (1975)
Robbins's theory gained attention beyond academia with Bradley Efron and Carl Morris's 1975 paper "Data Analysis Using Stein's Estimator and its Generalizations."
They tackled the problem of predicting full-season batting averages from just 45 at-bats early in the 1970 MLB season. Remarkably, instead of using each player's individual stats (45-AB average), "shrinkage" estimates — pulled toward the group mean — turned out to be closer to actual end-of-season averages.
The mathematical basis for this phenomenon is the 💡 James-Stein Estimator:
Where is the overall mean, is the number of simultaneously estimated parameters (), and is the variance of individual estimates. This estimator always has smaller mean squared error (MSE) than the individual maximum likelihood estimator (MLE). This is called Stein's paradox, and since Charles Stein proved it in 1961, it remains one of the most counterintuitive yet powerful results in modern statistics.
The implication for EXAWin is clear: Estimating each project's success rate from that project's data alone is mathematically guaranteed to be inferior to extracting structural patterns from the company's entire project pool and using them to calibrate each project's estimate.
4.3 Hyperparameter Estimation via Method of Moments
One of the core techniques of Empirical Bayes is 💡 Method of Moments for hyperparameter estimation. When dozens of projects have concluded and the distribution of actual success rates is observed, the Beta distribution's parameters can be calculated inversely from that distribution's mean and variance.
Let be the sample mean and the sample variance of observed success rates:
The insight this formula reveals lies in control over variance ().
First, interpreting the structure of :
- Small variance (all projects show similar success patterns): gets large → Strong Prior → System is confident in the company's pattern
- Large variance (results vary wildly across projects): gets small → Weak Prior → System responds more sensitively to each project's individual data
This automatic adjustment mechanism is the process of the system listening to the voice of the company's data. "Our company's sales patterns are consistent, so trust past experience more" or "Results vary too much project to project, so respect each deal's field data more" — these strategic judgments are made automatically by the system.
4.4 Precise Estimation via MLE
A statistically more efficient method than moments (capable of more accurate estimation with less data) is 💡 Maximum Likelihood Estimation (MLE).
If projects each had trials with successes, the marginal likelihood is:
Where is the Beta function. Finding the , that maximize this likelihood yields the Prior best fitting the data. Expanding the log-likelihood:
Differentiating using the digamma function :
This system of equations has no analytical solution and must be solved numerically via Newton-Raphson or fixed-point iteration. EXAWin automatically runs this MLE estimation at Phase 3 with sufficient data accumulation, precisely calibrating the Method of Moments estimate.
Chapter 5. EXAWin's Intelligent Evolution Roadmap
Data gains vitality as it accumulates. EXAWin divides parameter learning strategy into 5 stages (Phases) according to the company's data maturity. This is not an arbitrary division but a design reflecting the transition from the 💡 law of small numbers to the 💡 law of large numbers.
One key principle: The lesser count of Won and Lost (min) determines the overall confidence tier. Even with 50 Won, if there are only 3 Lost, there's insufficient basis to learn "Lost patterns." Analyzing only winning games while ignoring losses and then discussing tactics is not worthy of a coach — same principle.
| Phase | Grade | min(Won, Lost) | Learning Scope | Design Rationale |
|---|---|---|---|---|
| ❌ Phase 1 | Impossible | < 5 | Analysis impossible | Binomial test power virtually 0 at |
| 🟠 Phase 2 | Minimal | 5 ~ 9 | Display only (Apply locked) | Directional reference only, extreme overfitting risk |
| ✅ Phase 3 | Moderate | 10 ~ 19 | Impact, T, k + MCMC | CLT begins operating, MCMC executable (possible convergence instability) |
| 🟢 Phase 4 | Good | 20 ~ 49 | Full (Dampening, Silence included) + MCMC | Most parameters with high confidence |
| 🔵 Phase 5 | Excellent | 50+ | Full + MCMC stable convergence | Grid Search convergence, maximum MCMC posterior confidence |
Below we explain each Phase's statistical rationale and EXAWin's behavior; for complete technical anatomy, refer to the Auto-Tuner anatomy series:
Phase 1. Analysis Impossible (min < 5)
"An engine that hasn't yet opened its eyes"When Won or Lost is under 5, sample statistics are extremely unstable. 2 successes out of 3 attempts gives a sample success rate of 66.7%, but concluding the company's structural win rate is 67% based on this is like flipping a coin three times, getting two heads, and declaring "this coin has a 67% probability of landing heads."
In this period, EXAWin:
- Administrators manually set , based on the company's historical success rate and industry benchmarks
- The system visually displays the meaning of the configured Prior (expected value, confidence interval)
- No automatic analysis — a period of respecting human judgment
Phase 2. Directional Reference (min 5 ~ 9)
"The engine begins to open its eyes — but its hands are still tied"When the minimum data requirement (Won ≥ 5 AND Lost ≥ 5) is met, the Auto-Tuner begins displaying analysis results for the first time. Signal Lift, Impact recommendations, and T/k recommendations are computed, but the Apply button remains locked. Estimates at this stage carry extremely high overfitting risk.
The width of the 95% confidence interval for binomial proportion estimation at is approximately percentage points. Saying "3 wins in 5 means 60% success rate" actually means the true value could be anywhere between 17% and 93% — too wide a net to call it prediction.
Phase 3. Major Parameter Adjustment (min 10 ~ 19)
"The eye of discrimination opens"When min(Won, Lost) ≥ 10 is achieved, the Central Limit Theorem (CLT) causes the sampling distribution of the mean to begin converging to a normal distribution. From this point, Method of Moments estimation is statistically justified, and the Auto-Tuner unlocks Apply for the three core parameters: Impact, T, k.
However, fine-tuning parameters like Dampening and Silence Penalty are not yet adjusted. Isolating optimal values for these parameters requires richer data — moving too many parameters simultaneously with too little data leads to the overfitting trap.
Phase 4. Full Parameter Unlock (min 20 ~ 49)
"The engine begins adjusting its own fuel"When 20+ data points have accumulated on both sides, the law of large numbers begins to take full effect. In this period, EXAWin optimizes the remaining two parameters — Dampening (simultaneous signal attenuation ratio) and Silence Penalty (silence penalty intensity) — via Grid Search.
Additionally, Method of Moments estimates and Grid Search optima are cross-checked using K-fold Cross-Validation. If the gap between training separation and validation separation is large, an overfitting warning is issued; if the gap is small, the recommendation's generalizability is deemed high.
Phase 5. Statistical Stability + MCMC Stable Convergence (min 50+)
"A mature engine's self-governance"When 50+ data points have accumulated on both sides, MLE estimation achieves asymptotic efficiency. This means no unbiased estimator with smaller variance than MLE exists, guaranteed by the 💡 Cramér-Rao Lower Bound:
Where is the Fisher Information.
In this Phase, EXAWin goes beyond Grid Search point estimates to estimate the posterior distribution of parameters via 💡 MCMC (Markov Chain Monte Carlo). MCMC runs from Phase 3, but at Phase 5 data is sufficient for the most stable convergence. Using Emcee (Affine-Invariant Ensemble Sampler), it samples the joint posterior of the (N+2)-dimensional parameter space — Impact values + Dampening + Silence Penalty — and provides HDI (Highest Density Interval) for each parameter ( = number of Impact types excluding No Signal, 8 in standard configuration).
While Grid Search finds "the single optimal point," MCMC draws "the uncertainty terrain around that point." When R̂ (convergence diagnostic) is close to 1.0, the chains are deemed converged, and narrow HDI indicates strong data confidence for that parameter.
In this period, EXAWin:
- Provides Grid Search point estimates + MCMC interval estimates simultaneously
- Monitors overfitting via K-fold cross-validation
- Reports overall discriminative power via ROC AUC
- Provides Prior , recommendation via Method of Moments (human approval mandatory, no auto-application)
- Data-driven — but the final application decision always rests with humans
Chapter 6. Evidence Maturity: The Process of Adding Weight to Predictions
6.1 Monotonic Accumulation of Evidence
As the data () observed across a project's lifecycle increases, the posterior distribution's total parameter sum increases monotonically. This means the posterior distribution's variance decreases monotonically:
As increases, the denominator dominates:
This mathematically proves that the Bayesian engine is more than a mere calculator — it is a "learning organism" that builds conviction as evidence accumulates.
6.2 Three Stages of Growth
| Stage | State | Description |
|---|---|---|
| 🌱 Early Stage | Information is scarce; reacts sensitively to small external stimuli. Probability predictions fluctuate across a wide range. | |
| 🌿 Growing Stage | Data direction emerges; predictions begin finding a solid center. Confidence intervals narrow. | |
| 🌳 Mature Stage | Overwhelming evidence secured; maintains "expert-level reliability" unshaken by typical noise. |
The width of the 95% confidence interval at each stage, calculated using the Beta distribution's quantile function:
If this width was 0.4 or more (40 percentage points) at the Early Stage, it typically converges to under 0.1 (10 percentage points) at the Mature Stage. This is the process of data adding the weight of conviction.
Chapter 7. Theoretical Guarantees: Why This System Can Be Trusted
7.1 Posterior Consistency Theorem
The most frequent criticism of Bayesian inference is "Isn't the Prior subjective?" The mathematical answer to this critique is 💡 posterior consistency.
Established by the work of Doob (1949), Schwartz (1965), and Ghosh and Ramamoorthi (2003), this theorem states that for every open neighborhood of the true value :
In other words, regardless of where the Prior is set (as long as it's not an extremely biased Prior), the posterior converges to the truth with probability 1 given sufficient data.This means "whether you initially set 20% or 50%, after 30 completed projects, the system reaches the same conclusion." The Prior is a starting point, not a destination. Because of this mathematical guarantee, EXAWin can accept a company's initial intuitive settings without fear.
7.2 Optimality Guarantee: Superior Even in Frequentist Risk
Empirical Bayes estimators are proven superior not only within the Bayesian framework but also from a frequentist perspective. Synthesizing the results of Robbins (1956) and Efron-Morris (1975): In simultaneous estimation problems with , the frequentist risk of the empirical Bayes shrinkage estimator is always less than that of MLE:
This inequality holds for all values of (admissibility). For any company simultaneously managing 3 or more projects, empirical Bayes is universally superior to individual estimation.
Epilogue: The Moment the Weight of Conviction Changes
In retrospect, EXAWin's Bayesian Prior configuration is not simply "a screen for entering two numbers."
It is the act of recording — in the most rigorous mathematical language — a company's unique intuition and empirical win rate, cultivated over decades in the market: intangible but real assets. And upon that record, each day's sales activities accumulate as new evidence, while the system respects the initial human settings yet ultimately corrects itself through the voice of data.
The weight of conviction that this process is logically, theoretically, and empirically justified did not come from one or two geniuses' brilliant intuitions. From Bayes's posthumous paper in 1763, through Robbins's empirical Bayes in 1956, Stein's paradox in 1961, Efron-Morris's shrinkage estimation in 1975, to Ghosh-Ramamoorthi's posterior consistency theorem in 2003 — it stands upon 260 years of mathematical guarantees proven line by line by the collective intelligence of the global academic community.
The moment users configure EXAWin's and , they quietly shake hands with this 260-year intellectual heritage.
References
Bayes, T. (1763). "An Essay towards Solving a Problem in the Doctrine of Chances." Philosophical Transactions of the Royal Society of London, 53, 370-418.
Robbins, H. (1956). "An Empirical Bayes Approach to Statistics." Proceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability, 1, 157-163.
Stein, C. (1956). "Inadmissibility of the Usual Estimator for the Mean of a Multivariate Normal Distribution." Proceedings of the Third Berkeley Symposium, 1, 197-206.
James, W. and Stein, C. (1961). "Estimation with Quadratic Loss." Proceedings of the Fourth Berkeley Symposium, 1, 361-379.
Efron, B. and Morris, C. (1975). "Data Analysis Using Stein's Estimator and its Generalizations." Journal of the American Statistical Association, 70(350), 311-319.
Casella, G. (1985). "An Introduction to Empirical Bayes Data Analysis." The American Statistician, 39(2), 83-87.
Gelman, A., Carlin, J.B., Stern, H.S., Dunson, D.B., Vehtari, A., and Rubin, D.B. (2013). Bayesian Data Analysis. 3rd Edition, CRC Press.
Ghosh, J.K. and Ramamoorthi, R.V. (2003). Bayesian Nonparametrics. Springer Series in Statistics.